Writing a pandas dataframe to cloud storage
In search of simple data sharing
I've often wanted a workflow where I could process data in a Jupyter notebook using pandas, then quickly upload the contents of the dataframe to the cloud to get an easily shareable URL.
This week I finally made that happen using Google Cloud Storage and some associated libraries. The most minimal version of the workflow is now as simple as:
df = pd.DataFrame(...somedata)
df.to_csv('gs://bucket_name/filename.csv')
With the file then available at storage.cloud.google.com/bucket_name/filename.csv
Since I had to get familiar with some new software along the way, I wanted to note down the process step-by-step.
The Google Cloud part
Make a Google Cloud account
Google Cloud is a set of entreprise and/or developer-focused cloud services, and so is not enabled for a standard Google account by default.
First I had to visit cloud.google.com and sign up for the service. This took me to the fairly complicated looking Google Cloud dashboard, where I created a new project named Datahub.
Create a publicly accessible storage bucket
I spent a while looking through all the different options until I found what I was looking for in the 'Storage' button under the Resources tab.
This took me to a less complicated looking screen where I could create a new cloud storage bucket. At some point I was prompted to add my credit card info, because Google Cloud is a paid product – though it will only cost a few cents per month for the low volume of data transfer that I'll need.
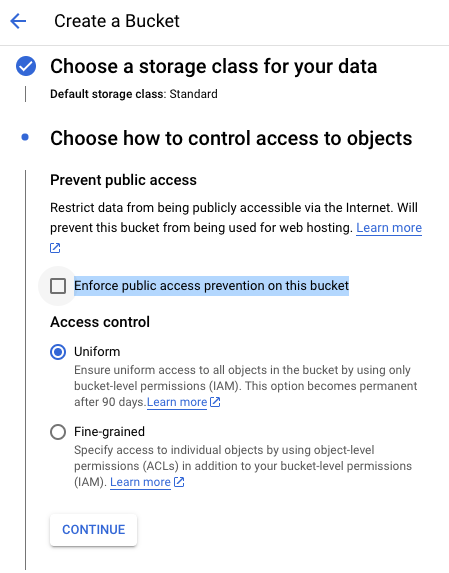
When creating the bucket I deselected the option to enforce public access prevention, meaning that data stored in the bucket will be viewable in read-only mode without authentication.
This would be risky security protocol for any sensitive information, but is fine for projects where we're sharing non-confidential data in order to collaborate on dataviz work.
The Python part
Install Google Cloud's CLI and Python library
Back on my local machine, I needed to install the Google Cloud CLI, and then set up Application Default Credentials (ADC) with the command line tool:
$ gcloud init
$ gcloud auth application-default login
The point of ADC is to store a set of credentials that can be accessed by the environment that the local code is running in, meaning there's no need to read a specific file containing application password, API key, etc.
After that, I needed to install the relevant libraries to interface with the cloud storage using Python.
First I installed the google-cloud-storage library into a new Conda environment (which is how I manage data journalism projects):
$ conda create --name cloud
$ conda install conda-forge::google-cloud-storage
Then I tried a code sample provided by Google to authenticate with a cloud storage bucket using the ADC credentials.
from google.cloud import storage
def authenticate_implicit_with_adc(project_id="your-project-id"):
storage_client = storage.Client(project=project_id)
buckets = storage_client.list_buckets()
print("Buckets:")
for bucket in buckets:
print(bucket.name)
print("Listed all storage buckets.")
This returned the name of my newly created storage bucket. Success!
Next I wanted to figure out the file upload.
Adapting examples from the Python documentation
The Google Cloud team has created a GitHub repo with code samples for interacting with cloud storage using Python.
After working through a few of those, I was able to write a simple, lightweight function to upload a dataframe to the cloud directly from memory (i.e. no need to read/write a local file first).
import pandas as pd
from google.cloud import storage
def upload_csv_to_gcloud(df,filename,project,bucket):
# Convert dataframe to CSV string buffer
csv = df.to_csv(index=False)
# Initialize GCS client
client = storage.Client(project=project)
bucket = client.get_bucket(bucket)
blob = bucket.blob(filename)
# Upload with content type specified
blob.upload_from_string(csv, content_type='text/csv')
df = pd.DataFrame({'letter':['a','b','c'],
'number':[1,2,3]})
upload_csv_to_gcloud(df,
'data.csv',
'my_cloud_project',
'cloud_bucket_name')
Bonus: use fs libraries to write directly from pandas
The code above is a flexible and readable way to achieve the goal, as it's clear what the function is doing, and easy to build in more functionality if we need it. But after reading some Stack Overflow I found a less explicit but much more simple way to achieve the same result.
First we need to install two more libraries:
fsspecso that pandas can read from and write to remote file systemsgcsfsas a file system interface specifically for Google Cloud Storage
Then all we need to do is:
df.to_csv('gs://bucket/filepath.csv')
And we can write our CSV file directly to the cloud!
We can't explicitly specify a file type with this method, so the file in the storage bucket is stored as type application/octet-stream rather than CSV or plaintext:

But downloading the file will render it as a conventional CSV, so in some cases this might be an acceptable trade for the sheer simplicity.
Overall though, once the initial set up is done, it's very quick either way!
© Corin Faife.RSS