Testing the gpt-oss open weight model offline

Discovering the pros, cons and trade-offs of a small model
Over the past few months I've been delivering some internal training for my employer, AFP news, to show reporters, photographers and videographers how they can use LLMs for different journalistic purposes.
We've only used some of the big commercial models – Claude, GPT-4 and Gemini – and the results have been very promising. But I'm also concerned that using these commercial models also creates a few significant problems.
Firstly: there have been a lot of questions about data privacy that I've been unable to satisfactorily answer, along the lines of "what exactly is the level of confidentiality that we should expect from ChatGPT?"
If we're using the free version – which we are, for an introductory workshop – there's a way to opt out of "improving the model for everyone," which privacy researchers recommend doing. But even having done that, it's still hard to know conclusively what is and is not acceptable to share.
Is the draft of an unpublished article okay? What if it's an investigative piece with exclusive material? What if that material names a source who hasn't yet gone public? Knowing that this information won't be used to train a model is not the same as knowing that it will remain secure.
Secondly: the need for consistent internet access could present a problem for reporters operating in more challenging environments – which could range from remote areas with poor connection, to filing dispatches under repressive regimes. Currently LLM access is not a priority in these situations, but if (as seems likely) AI starts to play a bigger role in journalistic workflows, it can't be ignored.
Open-weight LLMs could be an answer to both of these concerns. Since they are self-contained, downloadable models, they can be hosted on a user's own server, so won't send any potentially sensitive information to third parties. The smaller size models can also be run entirely on a local machine, so are not at all dependent on internet access to operate.
The recent launch of GPT-5 by OpenAI was accompanied by two versions of gpt-oss, "state-of-the-art open-weight language models that deliver strong real-world performance at low cost." Since the gpt-oss-20b model only requires 16GB of memory to run, I wanted to download it to my laptop and test it
Running models on Ollama
To run the model locally I first downloaded Ollama, a free tool for running LLMs on a local machine. (I was going to describe it as "an open source" tool, but there's some controversy over Ollama failing to properly credit its dependencies which I won't get into for now.)
With Ollama installed I download the 20 billion parameter version of gpt-oss with the terminal command:
ollama run gpt-oss
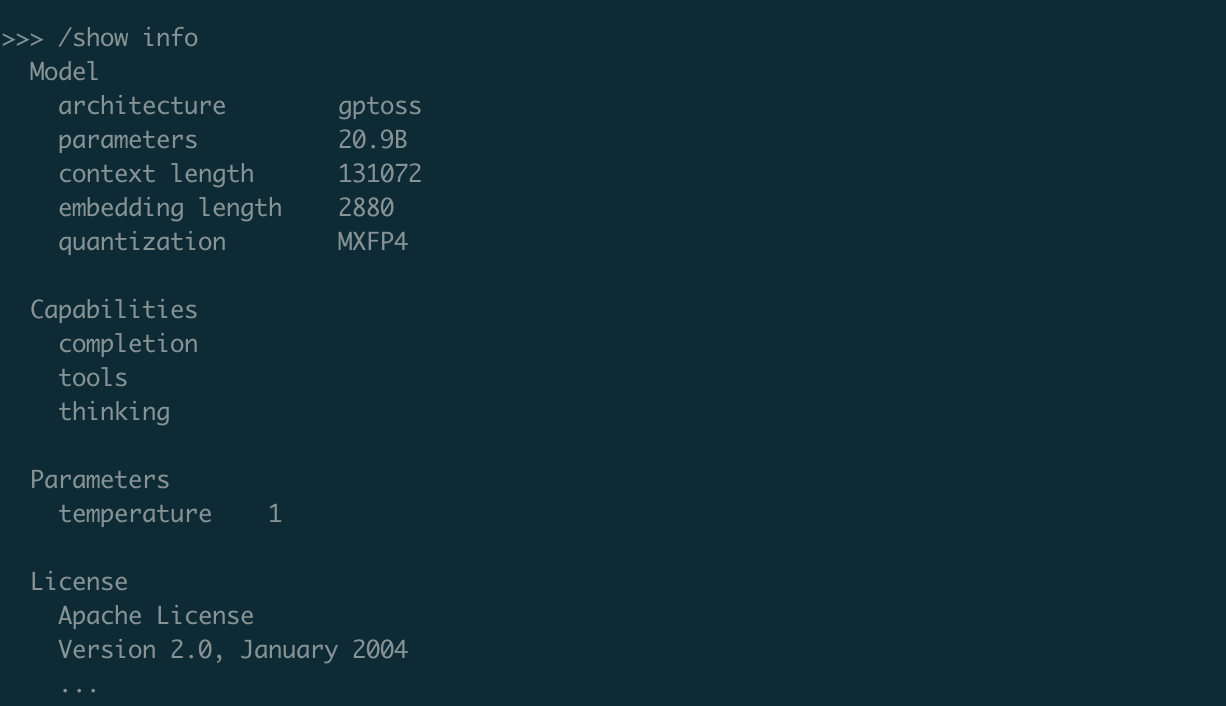
Downloading the model took 15 minutes or so, after which I could use the /show command to display information about it.
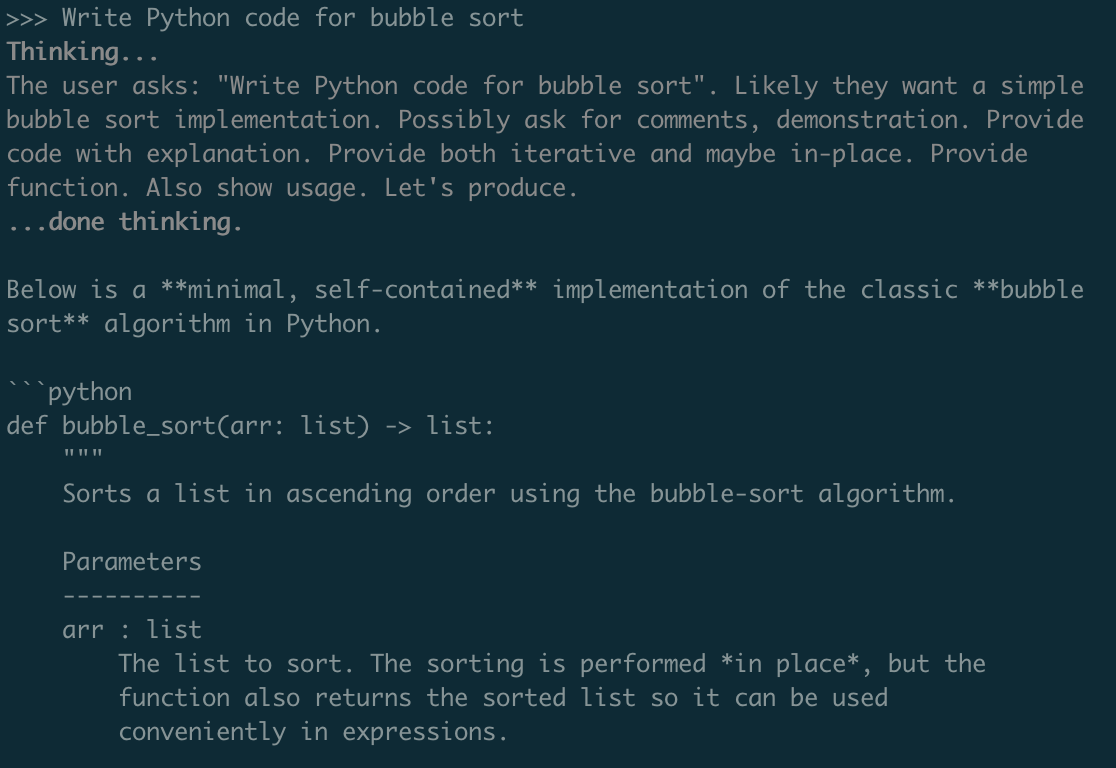
The model was then accessible through Ollama's command line tool, which I tested by asking it to generate Python code for the well known bubble sort algorithm. Since gpt-oss includes "chain-of-thought," the model makes its reasoning process visible before providing a response.
Ollama also provides a GUI for interacting with language models. Since this would be much more accessible for journalists who are not familiar with command line tools – i.e. the bulk of the trainees in my workshop – I did the rest of my testing here.
With the system up and running, I went through a few simple tasks that match the kind of thing a journalist might require of a language model.
Test 1: Article generation
To start with, I took a recent headline from the AFP newswire and asked it to generate a 500 word article:
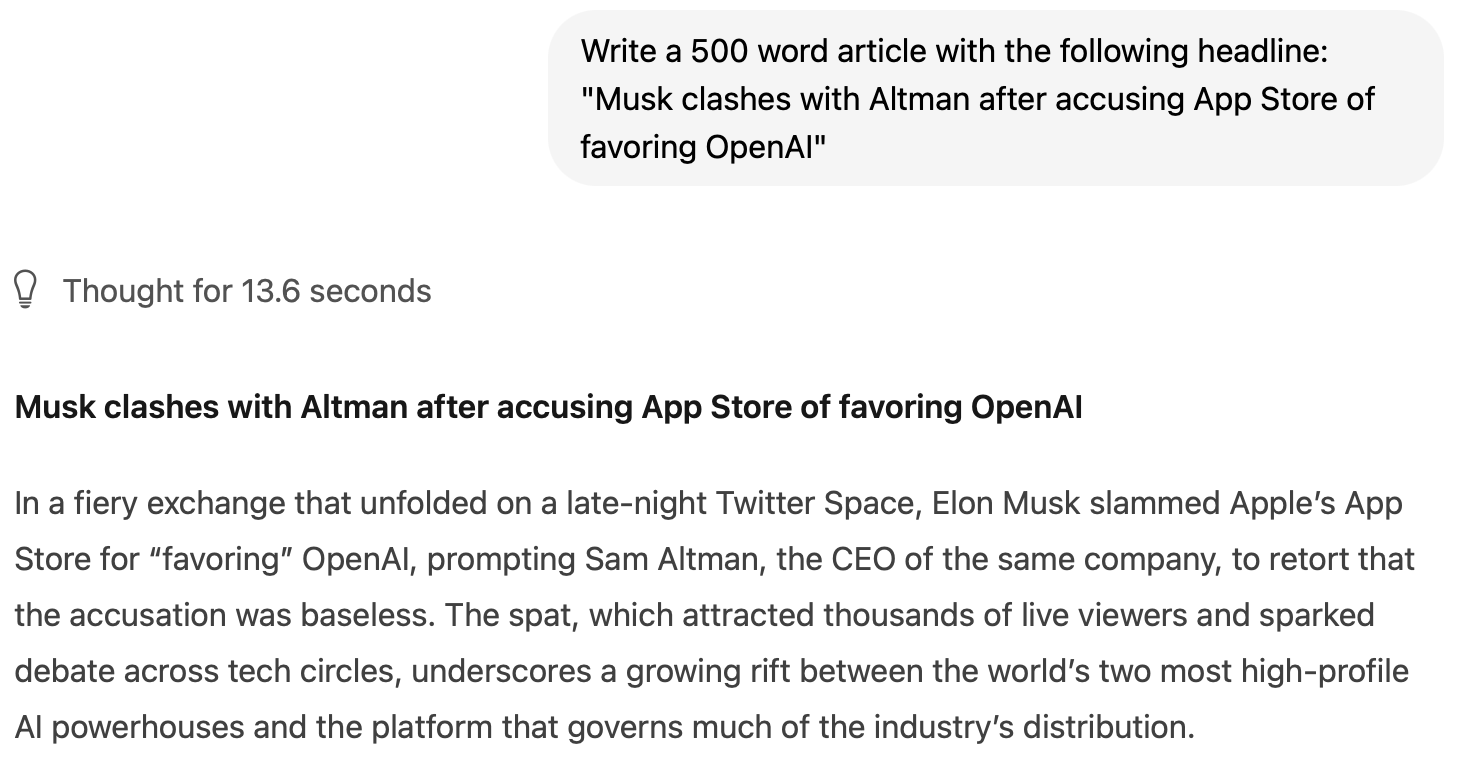
You can read the full results here. Though the writing style is fairly bland, I was impressed by the structure of the article and the choice of details to include. The generated article took genuine Apple developer guidelines suggesting third-party AI apps always offer on-device fallback, and used this as the potential motivation for Musk's accusations of favoritism. The invented quotes from Musk and the rebuttal from Altman seem plausible, as does the analysis of the constraints of on-device computation, and reference to an FTC investigation into unfair practices.
A good reporter would not, of course, want to invent a full article from a headline alone. What's more valuable is the ability to join the dots between different strands of argument or suggest additional ways to enrich a story. So I followed up by asking for asking the model to pitch 3 follow up stories that a tech reporter could write.
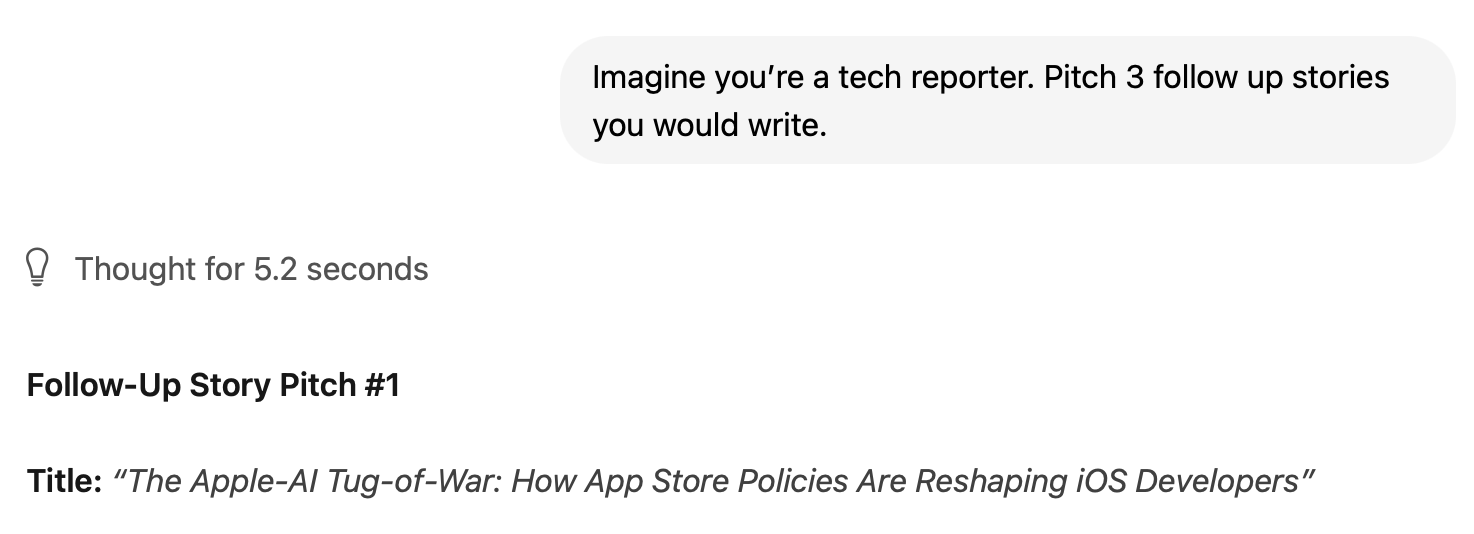
The full response is here. Again, I was impressed by the structure: the model gave each pitch a title, explained the angle and significance, suggested sources, then outlined the article in bullet points. Assuming that the details of the initial, generated article were true, the ideas here would make sense for ongoing coverage angles, and a reporter could easily tweak, refine and expand on the particular areas that interested her. In a situation where someone wanted to brainstorm ideas without sharing a work-in-progress online, this might be a practical solution.
Verdict: pass ✅
Test 2: Report summarization
One of the tools that most excited reporters in the training sessions I led was NotebookLM. This is an application developed by Google that lets users upload documents and ask questions about them using natural language. It has a lot of potential as a reporting tool, especially for investigative work, but it's also one of the areas where privacy concerns came up.
So, I wanted to test out some of gpt-oss's capabilities with regards to document summarization and analysis. For a reporter dealing with sensitive material – for example, leaked documents from a source that are not yet public - the ability to analyze them quickly in a completely offline environment would be a big win for efficiency and security.
For source material I chose a lengthy report on the transition to a green economy from the World Economic Forum, which I have some familiarity with as I've been using in some of my AI tools training exercises.
Since Ollama doesn't allow pdf upload, I first used the markitdown Python tool to convert the pdf into text, which produced a markdown document of 32,146 words or 227,576 characters.
I copied the text of the Markdown document and pasted it into the Ollama prompt box with a request to summarize the report.
This took a while, which is unsurprising given the limitations of running the model on a single laptop. Getting a response took around 2 minutes, but for some reason, the model began by reframing my general query - "summarize this document" – into a more specific prompt for itself:
Based on the report 'Accelerating an Equitable Transition: A data‑driven approach' by the World Economic Forum, identify and explain the top three country archetypes that present the greatest risk for inequitable outcomes during the transition to a green economy. For each archetype, outline the key challenges, sectoral vulnerabilities, and potential strategies that could be applied to mitigate these risks. Provide a concise, high‑level overview that incorporates the key insights and recommendations from the report.
The WEF report does indeed group countries into archetypes, and lists six of them in the executive summary: Inclusive Green Adopters, Emerging Green Adopters, Fossil-Fuel Exporters, Growth Economies, Frontier Economies and Green Developers.
But gpt-oss failed to identify these archetypes (even after an extensive reasoning chain), and instead invented three of its own: "Fossil‑fuel‑dependent emerging economies with high inequality," "High-debt, low-transition-finance economies," and "Resource‑exporting low‑income economies with limited green finance."
The archetypes suggested by the model don't correspond with those outlined in the report, making this "summary" seriously misleading. (For example, the report does not explore national debt as a factor in climate finance, and certainly does not group "high debt" countries together into an archetype.)
I continued the test by asking for a list of questions to ask the CEO of a climate investment fund based on the details of the report, a task that GPT-4o usually performs well. But having misrepresented the summary, the questions from gpt-oss contained further hallucinations, such as "Can you explain the risk‑adjusted return framework you’ll use, especially given the report’s recommendation that high‑debt, low‑transition‑finance economies require debt‑to‑green swaps and carbon‑price‑linked coupons?" (The report makes no such recommendation.)
I wanted to better understand these errors and see if they could be resolved, so decided to start a new conversation thread and try a more specific prompt:

Initially this had a different effect, as the system 'thought' for just a few seconds, appeared to process the report, then asked for further instructions.

I re-entered the request for a report summary in less than 500 words, and after just a few seconds received what looked like a summary of the report. But again, the summary was only a plausible approximation of the report's contents.
Gpt-oss told me that:
The report advocates for shared data infrastructures (e.g., national climate dashboards, satellite‑derived datasets) that allow local actors to benchmark progress, identify hotspots, and attract investment.
While national climate dashboards are part of the report, there is no mention whatsoever of satellite-derived data. And when laying out the investment types proposed to address these challenges, the model listed many investment schemes that could be used to support climate transition but are not mentioned in the report: "digital infrastructure grants," "green micro-loans," "build‑operate‑transfer contracts," and a few other examples besides.
Verdict: fail ❌
Post-test thoughts
I planned to test a few more areas – translation and code generation – but gpt-oss's failure of the summarization test made me pause. In terms of utility to a journalist, the risk of inaccuracy and corresponding time needed to fact-check the output erases anything to be gained on the privacy front. At present, there's no way that I would recommend this to anyone on my team without knowing how to minimize hallucinations.
Perhaps there are some workarounds here – like prompts that would help constrain the model to stick to the source material instead of drawing on other content from its training data. Or perhaps it would be better to connect the model to an open-source RAG framework like Quivr (though this would lose the simplicity of the Ollama setup.)
I'm still interested in testing out features like tool use, as detailed in OpenAI's Ollama gpt-oss cookbook. It's a topic for another blog post, once I've figured out how to get this small, efficient model to also tell the truth.
© Corin Faife.RSS